

ก้าวใหม่ของ ‘AI’ จาก ‘Big Data’ สู่ ‘Good Data’ เมื่อข้อมูลเยอะไม่สำคัญเท่าข้อมูลคุณภาพดี

“Software is eating the world”
ประโยคคลาสสิกของ Marc Andreessen ผู้ก่อตั้ง Netscape ที่กล่าวไว้เมื่อปี 2011
ผ่านมาสิบกว่าปี เราได้เข้าสู่ยุคที่เรียกว่า “Data is eating the world” ข้อมูลคือทรัพยากรสำคัญอันดับต้นๆที่ใช้ขับเคลื่อนธุรกิจและโลกในปัจจุบัน
Big data คือคำที่เราใช้เรียกยุคแห่งการเปลี่ยนแปลงที่ถูกผลักดันด้วยเทคโนโลยีใหม่ๆ อย่าง cloud computing, artificial intelligence (AI) และ machine learning (ML)
Cloud ช่วยให้การทำงานด้านซอฟต์แวร์และการใช้งาน infrastructure ต่างๆ ง่ายและสะดวกสบายกว่าเมื่อก่อน เปลี่ยนไอเดียเป็นสินค้าและบริการจริงได้อย่างรวดเร็ว ธุรกิจสามารถ scale ระบบเพื่อรองรับข้อมูลได้อย่างไม่จำกัด
ส่วนเทคโนโลยี AI และ ML ช่วยให้เราวิเคราะห์และนำข้อมูลจำนวนมหาศาล มาใช้ให้เกิดประโยชน์ได้ แบบที่ไม่เคยทำได้มาก่อน
McKinsey คาดการณ์ว่า AI จะเข้ามาเปลี่ยนแปลงธุรกิจ ตั้งแต่งานสาย retail การท่องเที่ยว การขนส่ง ยานยนต์ เทคโนโลยี การตลาดและโฆษณา ฯลฯ และภายในปี 2030 จะสร้างมูลค่าให้กับโลกสูงถึง 13 ล้านล้านเหรียญสหรัฐฯ
แต่ AI จะไม่สามารถไปถึงจุดสูงสุดของมัน หากวันนี้เราไม่เปลี่ยนวิธีการคิดและการทำงานของเรา จาก Model-Centric เป็น Data-Centric AI
ทำไมเราต้องเปลี่ยนมาเป็น Data-Centric AI
เมื่อเดือน มิ.ย. 2022 ที่ผ่านมา Andrew Ng ผู้ก่อตั้ง Google Brain และ Coursera โรงเรียนออนไลน์ (MOOC) ที่แรกของโลก ได้ขึ้นพูดที่งาน Databricks Data+AI Summit โดยหัวใจหลักของทอล์กนี้คือการผลักดันเรื่อง Data-centric AI
“AI cannot reach its full potential until it’s accessible to everyone.”
ในมุมมองของ Andrew นั้น AI จะเกิดประโยชน์สูงสุดต่อเมื่อทุกคนสามารถเข้าถึงมันได้อย่างง่ายดาย
แล้วพวกเราจะช่วยให้เกิดสิ่งนี้ได้อย่างไร ? ก่อนอื่นต้องทำความเข้าใจวิธีทำงาน AI Workflow แบบเก่ากันก่อน
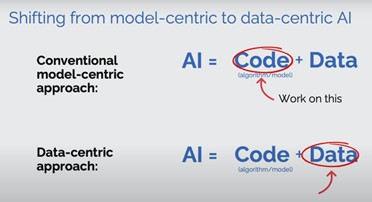
ในช่วงสิบกว่าปีที่ผ่านมา เราใช้ Model-Centric approach ในการสร้าง AI และพัฒนาโมเดล ML โดยเรามองข้อมูลเป็น fixed asset และพยายามปรับจูน code/ algorithm ที่เราเขียน เพื่อให้ได้โมเดลมีประสิทธิภาพสูงสุด
ขณะเดียวกัน Andrew ให้ความเห็นว่า workflow การทำงานแบบเก่า ยังไม่ใช่วิธีที่มีประสิทธิภาพสูงสุด และเสนอแนวทางใหม่ที่เรียกว่า Data-Centric AI ที่เราจะ hold our code/ algorithm fixed และเปลี่ยนโฟกัสไปที่การปรับจูนตัวคุณภาพข้อมูลแทน
Andrew ให้นิยามคำว่า Data-Centric AI ว่า “… the discipline of systematically engineering the data used to build an AI system.”
ในนิยามของ Andrew จะเห็นว่า ความสำคัญอยู่ที่การ engineering the data หรือ การสร้างและออกแบบข้อมูลที่มีคุณภาพสูง (good data) ก่อนจะนำไปรันกับ code/algorithm ที่ในปัจจุบันทำงานได้ดีมากๆ

ในช่วง 2-3 ปีที่ผ่านมา AI เรามีสิ่งที่เรียกว่า Foundation Models คือ AI algorithms ที่ถูกสร้างขึ้นมาจากข้อมูลขนาดใหญ่มากๆ แบบที่คนทั่วไปไม่สามารถเข้าถึงได้ เช่น BERT, GPT-3 หรือโมเดลล่าสุดอย่าง DALL-E ที่เป็นพื้นฐานของ Midjourney ซึ่งเป็น AI สร้างรูปภาพที่กำลังได้รับความนิยมสูงมากในช่วงนี้
งาน foundation models มักจะมาจากบริษัท Big Tech เป็นหลัก เช่น Google, Apple, DeepMind, OpenAI เป็นต้น
Midjourney (text-to-image generation) เป็นตัวอย่างที่ดีมากของ data-centric AI ตัวโมเดลที่ทีม midjourney เขียนขึ้นและถูกพัฒนาได้ดีมากแล้ว (จากข้อมูล text <-> image จำนวนมหาศาล) และสิ่งที่จะช่วยให้โมเดลทำงานได้ดีกว่านี้ขึ้นไปอีกคือ ข้อมูลใหม่ที่มีคุณภาพสูง
ลองจินตนาการว่า ถ้าผู้ใช้งาน midjourney หลายแสนคนทั่วโลกสามารถให้ feedback ได้ว่า รูปที่สร้างขึ้นมาตรงกับคำสั่งหรือ prompt ที่เขียนบอกไปหรือไม่ เราน่าจะได้เห็น midjourney เวอร์ชันต่อไป ที่ทำสิ่งยิ่งใหญ่ได้มากกว่าเดิมแน่นอน
แล้ว Good Data หน้าตาเป็นอย่างไร

ไม่ใช่ทุกคนหรือทุกบริษัทในโลกนี้ โดยเฉพาะ SMEs หรือ Startups ที่จะเข้าถึงข้อมูลขนาดใหญ่แบบที่ Google, Facebook หรือ OpenAI มี แต่อย่าเพิ่งหมดหวัง เพราะ data-centric AI approach ที่ Andrew ผลักดันอยู่ในขณะนี้ เกิดขึ้นมาเพื่อรับมือกับปัญหานี้โดยเฉพาะ โดย Andrew เสนอว่า ข้อมูลที่มีคุณภาพดีต้องมีคุณลักษณะ 3 ประการ คือ
- มีความต่อเนื่องและติด labels ได้อย่างถูกต้อง (Consistent and Accurate)
- ตัวแปรต้นในโมเดลมีคุณภาพสูง เหมาะสมกับปัญหาที่เรากำลังศึกษา (Representative)
- ข้อมูลความสะท้อนการเปลี่ยนแปลงของความสัมพันธ์ระหว่างตัวแปรต้นและตัวแปรตามในโมเดล (Reflects post deployment changes)
ถ้ามีคุณภาพครบตามนี้ Andrew บอกว่า ถึงแม้ข้อมูลจะมีขนาดเล็กมากๆ แบบ 50-100 รูปภาพ เราก็สามารถสร้าง AI models ที่ใช้งานได้ดีในระดับที่น่าพอใจเลยทีเดียว
ตัวอย่างโปรเจกต์ที่ Andrew ทำที่ Landing AI เช่น Supervised Learning การทำนายเม็ดยาที่มีตำหนิ หรือการค้นหาน็อต ตะปู หรือสิ่งแปลกปลอมที่ปนไปกับขนมหรืออาหารที่ผลิตในโรงงาน
Data-Central Approach: AI = Code + Data
เป้าหมายของ Andrew คือการสร้าง vertical platforms ที่ช่วยให้ผู้ประกอบการ หรือใครก็ตามที่อยากจะสร้างโมเดล AI/ ML สามารถสร้างโมเดลที่มีคุณภาพ ใช้งานได้จริง ถึงแม้ว่าจะมีข้อมูลไม่เยอะมาก ด้วยการใช้ fixed models (เช่น foundation models) และโฟกัสที่การ engineering data แทน
จาก Big Data สู่ Good Data ก้าวใหม่ของยุค AI
ประโยคหนึ่งที่ Andrew พูดในทอล์กที่สำคัญมากคือ การทำความสะอาดข้อมูล จากสถิติหลายแห่งพบว่า เวลา 80% ของพวกเรา หมดไปกับการเตรียมข้อมูลให้พร้อมสำหรับการทำโมเดล
“80% of our work is improving the data and that’s the core part of machine learning development”
Andrew อธิบายเรื่องกระบวนการทำงานของ ML workflow ว่า แบ่งได้สามขั้นตอนหลักๆ คือ
- Train model
- Error analysis
- Tune model -> Tune data
ในขั้นตอนที่สาม Andrew เสนอให้เปลี่ยนจาก tune model เป็น tune data (เพราะเรา hold our code/ algorithm fixed) การโฟกัสที่คุณภาพของข้อมูลจะช่วยยกระดับโมเดลเราได้อย่างมีนัยสำคัญ
Tuning data หรือการทำ cleaning data & engineering data ไม่ควรจะเป็นการทำครั้งเดียวจบก่อนเราเทรนโมเดล (model centric ที่ผ่านมาเป็นแบบนั้นเลย) แต่ควรจะเป็นกระบวนการที่ทำซ้ำเรื่อยๆ ใน ML workflow เราต้องเปลี่ยนมาโฟกัสที่ data ไม่ใช่ model
“มีข้อมูลเยอะไม่สำคัญเท่ากับมีข้อมูลที่ดีและมีคุณภาพ”
ในฐานะนักวิเคราะห์ข้อมูล (datarockie.com) ผมเห็นด้วยทุกอย่างที่ Andrew พูดในงาน Data+AI Summit ในปัจจุบัน AI algorithms มีความสามารถที่สูงมากๆ (high maturity) การทำ data cleaning หรือ data engineering คือส่วนผสมสำคัญที่จะช่วยให้โมเดล AI/ ML ที่เราสร้างมีคุณภาพ แก้ปัญหาได้เหมาะสม สร้าง impact ให้กับธุรกิจและโลกได้อย่างที่มันควรจะเป็น
หลังจากอ่านบทความนี้จบแล้ว หวังว่าทุกคนจะเริ่มตั้งคำถามตอนเราทำงานว่า “เราจะทำข้อมูลเราให้ดีขึ้นกว่านี้ได้อย่างไร” (ไม่ใช่ “เราจะจูนโมเดลให้ดีขึ้นได้อย่างไร”)

อธิบายศัพท์
เพื่อช่วยให้ผู้อ่านเข้าใจบทความนี้ได้ดียิ่งขึ้น ผมได้เขียนอธิบายคำศัพท์เทคนิคัลในบทความนี้ไว้คร่าวๆ ดังนี้
Artificial Intelligence หรือ AI คือสาขาหนึ่งของ computer science ที่ศึกษาเกี่ยวเรื่อง intelligence ของคอมพิวเตอร์
Machine Learning หรือ ML เป็นหนึ่งในเครื่องมือที่ใช้ในการพัฒนา AI เราสามารถมอง ML เป็น subset ของ AI อีกทีก็ได้
Deep Learning เป็นหนึ่งใน ML algorithm ที่มีความสำคัญอันดับต้นๆ ของโลก data science ทุกวันนี้ เราใช้ deep learning สร้างนวัตกรรมและเทคโนโลยีใหม่ๆ หลายอย่าง ตั้งแต่ computer vision, natural language processing และการวิเคราะห์ข้อมูลแบบ unstructured แบบต่างๆ
Supervised Learning เป็นวิธีการสร้าง AI/ ML รูปแบบหนึ่ง ที่เรามีตัวแปรต้น (x) และตัวแปรตาม (y) และให้คอมพิวเตอร์ช่วยหาความสัมพันธ์ mapping y = f(x) ให้กับเราแบบอัตโนมัติ ผลลัพธ์ที่ได้จะออกมาเป็นโมเดลทำนาย i.e. prediction models
อ้างอิง
Data centric AI development from Big Data to Good Data (Databricks)
Don’t buy the big data A.I. hype (Fortune)
Andrew Ng Launches A Campaign for Data-Centric AI (Forbes)
ที่มาของรูปภาพ
Midjourney Portraits | Tips for Better AI Art | Betcha She Sews
(5) Data centric AI development From Big Data to Good Data Andrew Ng – YouTube

Future Trends
Knowing The Future, Be The Winners of Tomorrow การรู้อนาคตทำให้เราเป็นผู้ชนะของวันพรุ่งนี้